 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Semantic and Pixel Representations for Ultra-Low Bitrate Image Compression
Jun 01, 2026Most existing extreme compression methods fail to achieve an optimal rate-distortion-perception trade-off, as they typically prioritize perceptual fidelity and visual realism over pixel-level accuracy. Consequently, the resulting reconstructions often deviate noticeably from the originals. Ultra-low bitrate image compression is therefore crucial-not only for producing extremely compact representations but also for ensuring that reconstructed images remain semantically coherent and faithful to the source at the pixel level. To this end, we propose SPRDiff, a diffusion-based compression method that fully leverages both semantic and pixel representations, thereby enhancing reconstruction fidelity under ultra-low bitrate constraints. Specifically, we develop a triple-encoder architecture that utilizes high-fidelity features from the pretrained distortion-oriented and semantic-oriented encoders to compensate for the limited representations extracted by the frozen VAE encoder, thereby improving latent compression and entropy modeling. To further enhance the reconstruction fidelity of diffusion models, we introduce a distortion-aware reconstruction module with dual feature extraction. This module not only generates a coarse reconstruction that preserves the main structures, but also provides practical and accurate semantic- and pixel-level conditional signals to guide the diffusion model. Extensive experiments on benchmark datasets demonstrate that our method outperforms state-of-the-art approaches in the rate-distortion-perception tradeoff at extremely low bitrates (below 0.03 bpp), effectively preserving both perceptual quality and pixel-wise fidelity in the reconstructed images. We will release the source code and trained models at https://github.com/cshw2021/SPRDiff.
Tether-Aware Dynamic Collision Avoidance for USV-HROV Systems
May 31, 2026Heterogeneous marine robotic systems composed of an unmanned surface vehicle (USV) and a hybrid remotely operated vehicle (HROV) have shown great potential for subsea cable inspection. In such missions, the USV tracks the HROV at the surface while supplying power and communication through an umbilical tether. However, dynamic collision avoidance for the USV during HROV tracking is challenging because the submerged tether may scrape against passing vessels, while evasive maneuvers can enlarge the USV--HROV separation, thereby increasing the likelihood of tether tautness and compromising HROV operations. To address these challenges, this work proposes a tether-aware dynamic collision avoidance method for a USV tracking an HROV. First, a tether safety-aware planar domain is introduced to represent the three-dimensional collision risk between the tether and obstacle vessels without an explicit tether shape model. Second, a tether tautness-aware velocity obstacle method is developed to achieve safe avoidance while reducing the likelihood of tether tautness. Finally, the method is integrated with line-of-sight guidance to coordinate HROV tracking and collision avoidance. Gazebo-based simulations show that the proposed method avoids dynamic obstacle vessels while maintaining tether safety and reducing the likelihood of tether tautness during USV evasive maneuvers.
SAMIC: A Lightweight Semantic-Aware Mamba for Efficient Perceptual Image Compression
May 06, 2026Perceptual image compression focuses on preserving high visual quality under low-bitrate constraints. Most existing approaches to perceptual compression leverage the strong generative capabilities of generative adversarial networks or diffusion models, at the cost of substantial model complexity. To this end, we present an efficient perceptual image compression method that exploits the long-range modeling capability and linear computational complexity of state space models, with a particular focus on Mamba. Unlike existing methods that rely on an inherently fixed scanning order and consequently impair semantic continuity and spatial correlation, we develop a semantic-aware Mamba block (SAMB) to enable scanning guided by dynamically clustered semantic features, thereby alleviating the strict causality constraints and long-range information decay inherent to Mamba. Inspired by singular value decomposition, we design an SVD-inspired redundancy reduction module (SVD-RRM) that performs a low-rank approximation on the latent features by introducing a learnable soft threshold, leading to channel-wise redundancy information reduction. The proposed SAMB is integrated into both the encoder and decoder of the compression framework, whereas the SVD-RRM is incorporated only in the encoder. Extensive experiments demonstrate that our method performs favorably against state-of-the-art approaches in terms of rate-distortion-perception tradeoff and model complexity. The source code and pretrained models will be available at https://github.com/Jasmine-aiq/SAMIC.
Geometric Transformation-Embedded Mamba for Learned Video Compression
Mar 09, 2026Although learned video compression methods have exhibited outstanding performance, most of them typically follow a hybrid coding paradigm that requires explicit motion estimation and compensation, resulting in a complex solution for video compression. In contrast, we introduce a streamlined yet effective video compression framework founded on a direct transform strategy, i.e., nonlinear transform, quantization, and entropy coding. We first develop a cascaded Mamba module (CMM) with different embedded geometric transformations to effectively explore both long-range spatial and temporal dependencies. To improve local spatial representation, we introduce a locality refinement feed-forward network (LRFFN) that incorporates a hybrid convolution block based on difference convolutions. We integrate the proposed CMM and LRFFN into the encoder and decoder of our compression framework. Moreover, we present a conditional channel-wise entropy model that effectively utilizes conditional temporal priors to accurately estimate the probability distributions of current latent features. Extensive experiments demonstrate that our method outperforms state-of-the-art video compression approaches in terms of perceptual quality and temporal consistency under low-bitrate constraints. Our source codes and models will be available at https://github.com/cshw2021/GTEM-LVC.
Safe-SDL:Establishing Safety Boundaries and Control Mechanisms for AI-Driven Self-Driving Laboratories
Feb 13, 2026The emergence of Self-Driving Laboratories (SDLs) transforms scientific discovery methodology by integrating AI with robotic automation to create closed-loop experimental systems capable of autonomous hypothesis generation, experimentation, and analysis. While promising to compress research timelines from years to weeks, their deployment introduces unprecedented safety challenges differing from traditional laboratories or purely digital AI. This paper presents Safe-SDL, a comprehensive framework for establishing robust safety boundaries and control mechanisms in AI-driven autonomous laboratories. We identify and analyze the critical ``Syntax-to-Safety Gap'' -- the disconnect between AI-generated syntactically correct commands and their physical safety implications -- as the central challenge in SDL deployment. Our framework addresses this gap through three synergistic components: (1) formally defined Operational Design Domains (ODDs) that constrain system behavior within mathematically verified boundaries, (2) Control Barrier Functions (CBFs) that provide real-time safety guarantees through continuous state-space monitoring, and (3) a novel Transactional Safety Protocol (CRUTD) that ensures atomic consistency between digital planning and physical execution. We ground our theoretical contributions through analysis of existing implementations including UniLabOS and the Osprey architecture, demonstrating how these systems instantiate key safety principles. Evaluation against the LabSafety Bench reveals that current foundation models exhibit significant safety failures, demonstrating that architectural safety mechanisms are essential rather than optional. Our framework provides both theoretical foundations and practical implementation guidance for safe deployment of autonomous scientific systems, establishing the groundwork for responsible acceleration of AI-driven discovery.
One-Step Diffusion for Perceptual Image Compression
Feb 02, 2026Diffusion-based image compression methods have achieved notable progress, delivering high perceptual quality at low bitrates. However, their practical deployment is hindered by significant inference latency and heavy computational overhead, primarily due to the large number of denoising steps required during decoding. To address this problem, we propose a diffusion-based image compression method that requires only a single-step diffusion process, significantly improving inference speed. To enhance the perceptual quality of reconstructed images, we introduce a discriminator that operates on compact feature representations instead of raw pixels, leveraging the fact that features better capture high-level texture and structural details. Experimental results show that our method delivers comparable compression performance while offering a 46$\times$ faster inference speed compared to recent diffusion-based approaches. The source code and models are available at https://github.com/cheesejiang/OSDiff.
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
FAR-AVIO: Fast and Robust Schur-Complement Based Acoustic-Visual-Inertial Fusion Odometry with Sensor Calibration
Dec 23, 2025
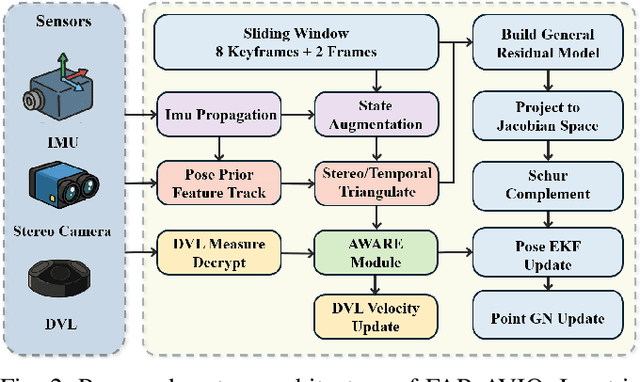
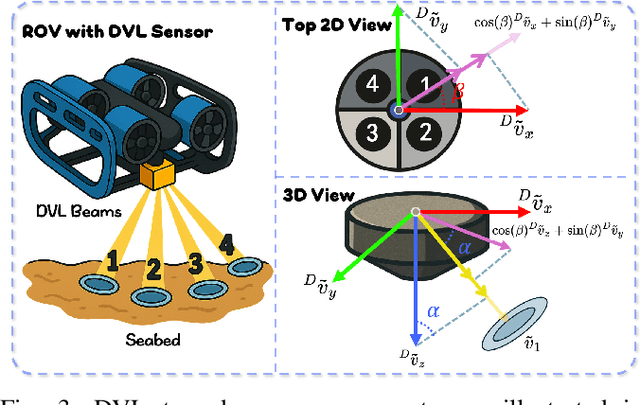
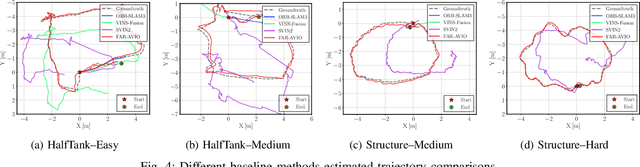
Underwater environments impose severe challenges to visual-inertial odometry systems, as strong light attenuation, marine snow and turbidity, together with weakly exciting motions, degrade inertial observability and cause frequent tracking failures over long-term operation. While tightly coupled acoustic-visual-inertial fusion, typically implemented through an acoustic Doppler Velocity Log (DVL) integrated with visual-inertial measurements, can provide accurate state estimation, the associated graph-based optimization is often computationally prohibitive for real-time deployment on resource-constrained platforms. Here we present FAR-AVIO, a Schur-Complement based, tightly coupled acoustic-visual-inertial odometry framework tailored for underwater robots. FAR-AVIO embeds a Schur complement formulation into an Extended Kalman Filter(EKF), enabling joint pose-landmark optimization for accuracy while maintaining constant-time updates by efficiently marginalizing landmark states. On top of this backbone, we introduce Adaptive Weight Adjustment and Reliability Evaluation(AWARE), an online sensor health module that continuously assesses the reliability of visual, inertial and DVL measurements and adaptively regulates their sigma weights, and we develop an efficient online calibration scheme that jointly estimates DVL-IMU extrinsics, without dedicated calibration manoeuvres. Numerical simulations and real-world underwater experiments consistently show that FAR-AVIO outperforms state-of-the-art underwater SLAM baselines in both localization accuracy and computational efficiency, enabling robust operation on low-power embedded platforms. Our implementation has been released as open source software at https://far-vido.gitbook.io/far-vido-docs.
INC: An Indirect Neural Corrector for Auto-Regressive Hybrid PDE Solvers
Nov 18, 2025



When simulating partial differential equations, hybrid solvers combine coarse numerical solvers with learned correctors. They promise accelerated simulations while adhering to physical constraints. However, as shown in our theoretical framework, directly applying learned corrections to solver outputs leads to significant autoregressive errors, which originate from amplified perturbations that accumulate during long-term rollouts, especially in chaotic regimes. To overcome this, we propose the Indirect Neural Corrector ($\mathrm{INC}$), which integrates learned corrections into the governing equations rather than applying direct state updates. Our key insight is that $\mathrm{INC}$ reduces the error amplification on the order of $Δt^{-1} + L$, where $Δt$ is the timestep and $L$ the Lipschitz constant. At the same time, our framework poses no architectural requirements and integrates seamlessly with arbitrary neural networks and solvers. We test $\mathrm{INC}$ in extensive benchmarks, covering numerous differentiable solvers, neural backbones, and test cases ranging from a 1D chaotic system to 3D turbulence. $\mathrm{INC}$ improves the long-term trajectory performance ($R^2$) by up to 158.7%, stabilizes blowups under aggressive coarsening, and for complex 3D turbulence cases yields speed-ups of several orders of magnitude. $\mathrm{INC}$ thus enables stable, efficient PDE emulation with formal error reduction, paving the way for faster scientific and engineering simulations with reliable physics guarantees. Our source code is available at https://github.com/tum-pbs/INC
Sparse3DPR: Training-Free 3D Hierarchical Scene Parsing and Task-Adaptive Subgraph Reasoning from Sparse RGB Views
Nov 11, 2025Recently, large language models (LLMs) have been explored widely for 3D scene understanding. Among them, training-free approaches are gaining attention for their flexibility and generalization over training-based methods. However, they typically struggle with accuracy and efficiency in practical deployment. To address the problems, we propose Sparse3DPR, a novel training-free framework for open-ended scene understanding, which leverages the reasoning capabilities of pre-trained LLMs and requires only sparse-view RGB inputs. Specifically, we introduce a hierarchical plane-enhanced scene graph that supports open vocabulary and adopts dominant planar structures as spatial anchors, which enables clearer reasoning chains and more reliable high-level inferences. Furthermore, we design a task-adaptive subgraph extraction method to filter query-irrelevant information dynamically, reducing contextual noise and improving 3D scene reasoning efficiency and accuracy. Experimental results demonstrate the superiority of Sparse3DPR, which achieves a 28.7% EM@1 improvement and a 78.2% speedup compared with ConceptGraphs on the Space3D-Bench. Moreover, Sparse3DPR obtains comparable performance to training-based methods on ScanQA, with additional real-world experiments confirming its robustness and generalization capability.